
NVIDIA Prediksi Permintaan Komputasi Mencapai Triliunan Dolar Hingga 2027
Ruang Press - Jensen Huang mengumumkan platform Vera Rubin di GTC 2026 kemarin, mengklaim bahwa kinerja inferensi per unit daya telah meningkat 10 kali lipat dibandingkan Blackwell, biaya Token inferensi telah turun menjadi sepersepuluh, dan memperkirakan bahwa pesanan gabungan antara Blackwell dan Vera Rubin akan mencapai lebih dari 1 triliun dolar sebelum tahun 2027.
Dalam dua tahun terakhir, biaya inferensi API setara GPT-4 telah turun 94%, dari 36 dolar per juta Token menjadi kurang dari 2 dolar. Secara intuitif, daya komputasi menjadi lebih murah, perusahaan seharusnya mengeluarkan lebih sedikit uang. Namun, pengeluaran modal dari empat penyedia cloud, yaitu Amazon, Alphabet, Meta, dan Microsoft, telah meningkat dari 154 miliar dolar menjadi 416 miliar dolar, hampir tiga kali lipat.
Prediksi triliun dolar dari Jensen Huang bukanlah sekadar strategi pemasaran; di baliknya ada kurva yang dapat digambarkan dengan data.
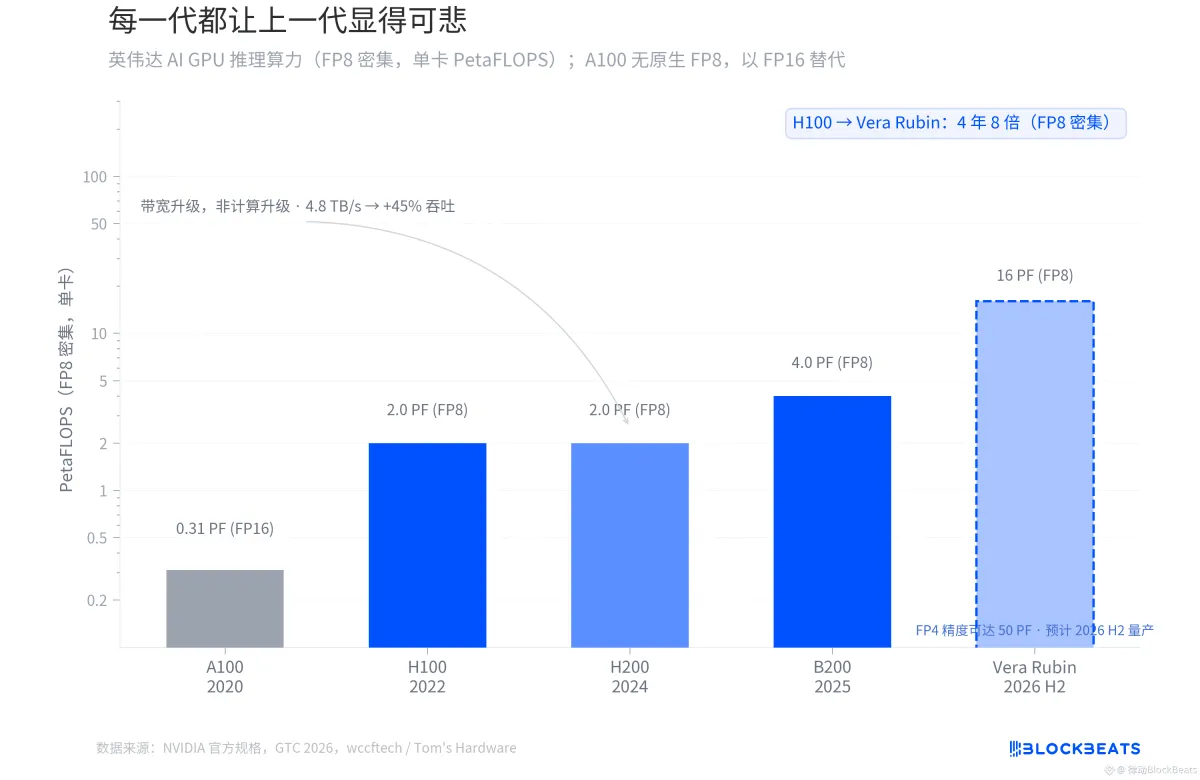
Setiap generasi membuat generasi sebelumnya tampak menyedihkan.
Dari H100 pada tahun 2022 hingga Vera Rubin yang akan diproduksi massal pada paruh kedua tahun 2026, kekuatan inferensi FP8 dari GPU AI NVIDIA telah meningkat 8 kali lipat dalam empat tahun. Menurut spesifikasi resmi NVIDIA, H100 memiliki 2,0 PetaFLOPS per kartu, B200 mencapai 4,0 PF, dan Vera Rubin langsung melompat ke 16 PF.
Namun tidak setiap lompatan generasi berasal dari tempat yang sama. Menurut laporan wccftech, inti perhitungan H200 dan H100 sama persis, dan tidak ada perubahan dalam kekuatan FP8, semua peningkatannya berasal dari bandwidth memori (dari 3,35 TB/s meningkat menjadi 4,8 TB/s), yang menghasilkan peningkatan throughput inferensi sekitar 45%.
Perubahan arsitektur yang nyata terjadi pada B200 dan Vera Rubin. Vera Rubin menggunakan proses 3nm dari TSMC, dengan desain dual chiplet yang dilengkapi 336B transistor, dan kekuatan inferensi pada akurasi FP4 mencapai 50 PF. Menurut laporan Tom's Hardware, sistem Vera Rubin pertama sudah berjalan di Microsoft Azure.
Di sini ada perbedaan yang mudah diabaikan. Apa yang dikatakan Jensen Huang di GTC tentang "10 kali lipat" merujuk pada penurunan biaya Token inferensi, bukan kelipatan kekuatan komputasi asli. Biaya Token mencakup optimasi Transformer Engine, akurasi FP4, dan inferensi batch yang lebih besar, serta faktor sistem lainnya. Dari TFLOPS FP8 padat yang distandarisasi, Vera Rubin relatif 4 kali lipat dibandingkan Blackwell, dan 8 kali lipat dibandingkan H100.
Kemiringan kurva ini tidak pernah melambat. Setiap generasi GPU membuat generasi sebelumnya tampak tidak memadai, dan inilah titik awal dari cerita yang akan datang.
Paradoks Jevons: semakin murah kekuatan komputasi, semakin banyak yang dibelanjakan.
Pada bulan Maret 2023, saat GPT-4 baru diluncurkan, biaya panggilan API adalah sekitar 36 dolar per satu juta Token. Menurut catatan harga resmi OpenAI, hingga pertengahan 2024 saat GPT-4o diluncurkan, harganya turun menjadi sekitar 7 dolar, dan pada akhir 2025, harga yang sebenarnya dapat digunakan sudah di bawah 2 dolar. Dalam dua tahun, penurunannya lebih dari 94%.
Menurut logika umum, jika biaya inferensi turun begitu banyak, perusahaan seharusnya mengeluarkan lebih sedikit. Namun, kenyataannya sama sekali berlawanan. Menurut laporan perusahaan dan data yang dilacak oleh Platformonomics, pengeluaran modal tahunan dari empat penyedia cloud, yaitu Amazon, Alphabet, Meta, dan Microsoft, meningkat dari 154 miliar dolar pada 2023 menjadi 416 miliar dolar pada 2025, dengan peningkatan 170%. Di mana Google secara terpisah meningkat dari 32 miliar menjadi 91,5 miliar (sekitar 2,9 kali lipat), dan peningkatan Microsoft bahkan lebih besar.
Fenomena ini memiliki nama dalam ekonomi, disebut paradoks Jevons. Pada tahun 1865, ekonom Inggris William Jevons menemukan bahwa mesin uap yang ditingkatkan oleh Watt meningkatkan efisiensi penggunaan batu bara secara signifikan, tetapi konsumsi batu bara di Inggris justru meningkat. Alasannya sangat sederhana, peningkatan efisiensi membuat mesin uap menjadi lebih ekonomis, sehingga lebih banyak industri mulai menggunakan mesin uap, dan total permintaan melonjak jauh melampaui bagian penghematan efisiensi.
Hari ini, situasi inferensi AI sama persis. Harga API turun menjadi 6% dari yang sebelumnya, perusahaan tidak menghemat anggaran karena hal ini, tetapi mulai memasukkan AI ke dalam skenario yang sebelumnya tidak ekonomis. Layanan pelanggan, pemeriksaan kode, generasi konten, pengurutan ulang pencarian, penawaran iklan; setiap skenario baru mengonsumsi lebih banyak kekuatan inferensi. Kecepatan pertumbuhan permintaan jauh melampaui kecepatan penurunan biaya. DeepSeek R1 pada awal 2025 menekan harga input menjadi 0,55 dolar per satu juta Token, semakin mempercepat siklus ini. Dua garis yang bergerak berlawanan di grafik tersebut adalah dua sisi dari hal yang sama.
Tiga tahun 11 kali lipat, dan tidak melihat batas atas.
Kemudian Jensen Huang di GTC 2026 mengatakan: "Hingga 2027, saya melihat pesanan yang terlihat setidaknya mencapai 1 triliun dolar. Sebenarnya, kapasitas kami tidak akan mencukupi. Saya yakin permintaan komputasi akan jauh melebihi angka ini."
Prediksi yang dia berikan tahun lalu di GTC adalah bahwa hingga 2026, pesanan yang terlihat sekitar 5000 miliar dolar. Setahun kemudian, angka tersebut berlipat ganda, dan jendela waktu hanya diperpanjang satu tahun. Analis memprediksi kisaran pendapatan untuk FY2026-FY2027 antara 1600-2200 miliar dan 2500-4000 miliar dolar. Namun, Jensen Huang sendiri mengatakan bahwa angka ini bukanlah batas atas, "permintaan komputasi akan jauh melebihi angka ini." Pada hari penutupan GTC, saham NVIDIA naik 4,3%. Pasar jelas memilih untuk mempercayainya.
Setiap generasi GPU membuat generasi sebelumnya tampak menyedihkan, setiap penurunan harga membuat pengeluaran modal generasi berikutnya tampak wajar. NVIDIA berdiri di posisi paling manis dari paradoks ini.
#AI
Recent News


Internasional







